0 O C
Notes about digitization of physical documents with a focus on Optical Character Recognition
Google-fingers and ScanOps • Overlooking Full-Text • Early Character Recognition Tech • Common Confusion • Machine-Usable Fonts • State-Of-The-Art 2020s • Artworks with OCR
Google-Fingers and ScanOps
In August 2010 Google announced that 129.864.880 books would exist in the entire world. The company also said, it would scan all those books. In Mountain View, California (USA), a building in the Googleplex has been equipped as a workplace for ScanOps—the company’s name for employees who do the digitization work.
More than ten years later, at least 25.000.000 books are stored somewhere at the company in a digital format. There is an index on the Internet you can search; often you get a preview and “snippets” appear. But only a fraction of the book collection is accessible as full-text. Due to legal reasons, it says. The large mass digitization project came to a halt. As it seems, G. is no longer hiring ScanOps. But the scanning has been done, hastily, it is on the record. The traces of humans holding, positioning and turning book pages will most likely always stay on the record. Around 2010 the Google-fingers, in hot-pink, became a symbol for the labor involved in the process of transforming three-dimensional material (library books) into something that suits the technorationalist ideology of access; “the idea that the presence of resources, made fundamentally discoverable through an uncomplicated search interface, constitutes access, full stop.” [1]


Page 27 from Des Ritters Carl von Linné vollständiges Natursystem, Nürnberg: Gabriel N. Raspe, 1773-1775. Via Aliza Elkin, Hand Job Zine No. 9 [2]
Links: Google-Fingers and ScanOps
- [1] Anna L. Hoffmann and Raina Bloom, Digitizing Books, Obscuring Women’s Work. Google Books, Librarians, and Ideologies of Access, in: Ada. A Journal of Gender, New Media, and Technology 9, 2016 ↩
- [2] Aliza Elkin, Hand Job Zine, since 2016 – Zine about mass digitization, labor, error & art. ↩
- Ulrike Bergermann, Digitus. Der letzte Finger, in: Zeitschrift für Medienwissenschaft. Web-Extra, 09/2016 – Article (in German) about the materiality in digitization work.
- Benjamin Shaykin, Special Collection, 2009-2013 – Books with partial recreations of books found on Google Books.
- Andrew Norman Wilson, Workers Leaving the Googleplex, 2011 – Video essay about ScanOps working at Google’s headquarters
- Krissy Wilson, The Art of Google Books, Blog, since 2011 – Collection of anomalies and curiosities found in the Google Books database.
Overlooking Full-Text
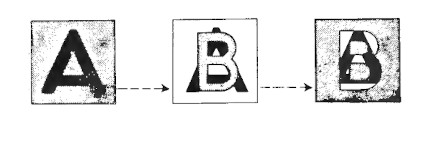
To become searchable, indexable and n-grammable through whatever interface, printed or hand-written documents have to go through different stages of translation and transcoding. In Optical Character Recognition, writing is mainly handled based on its visual qualities. The perception of figures and the recognition of these figures as part of an alphabet is a process that is, in humans, just the transient initial phase of what is called reading, pre-reading. With increasing experience, cognitive psychology shows, the logographic phase is only semiconscious and tantamount to overlooking. But how much and what exactly is a machine allowed or supposed to overlook?
The materiality of paper and ink: texture of the fiber, show-through of double-sided texts, dark background, heavy or light print, curved baselines. The typography: unusual typefaces, strange layouts, very small or large print, underlining, italics and spacing. The symbols: punctuation (commas, periods, quotation marks, diacritical marks), ligatures. Depending on the color and texture of the paper, it is not always easy for the computer to separate the print from the background. And if strokes are very thick, it assumes symbols run into each other (‘rn’ becoming ‘m’), if they are very thin, it assumes symbols break apart (‘h’ becoming ‘li’).
In the digital realm, the physical text appears “overfull”. I aim for the overfull-text, some kind of noise literature in the computer-age. To preserve and to sculpt the smudge.
Early Character Recognition Techniques
Main process: The source, typically symbols imprinted on paper, is positioned and illuminated. The source pattern becomes “input” through optical scanning. The input pattern is superimposed against a reference pattern. A match between input and reference pattern triggers an impulse.
Mask Matching
An input character is matched with a template, stencil or mask. The reference patterns are negatives of the characters. They are, for example, stenciled on a rotating disk. An input character is projected on the disk. Each time it fully matches a mask, light is extinguished to a photo-cell which turns the impulse into signals for further processing.
The principle was first described around 1930 for application in statistical machines and aid devices for blind readers. [3]
Peephole Matching
Instead of the full character, selected sub-areas of the reference pattern are used as a mask for matching.

Coordinate Matching
Characters are described in a coordinate grid. The encoding results in a string or sequence of binary symbols. Each bit position represents a cell on the grid. The pattern of a character is quantized, sometimes expressed in a probability matrix. Hardware in the 1960s: A reading matrix consisting of photo-cells that activate a shift register. [4]

Waveform Matching
A character is segmented into vertical sub-areas. Sampling of the input at discrete intervals is necessary. When scanned by a machine, characters produce dissimilar waveforms as a function of time.
The principle was first implemented in magnetic ink recognition (MICR) devices for banking purposes in mid-1950. A similar technique was basis for the optophone which introduced a tonal code for letters and numbers. [5]

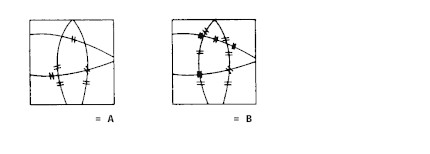
Vector Crossing
A vector space consisting of radial areas is constructed. Conductors are used for ‘sensing’ an intersection of an input and the reference space. It was mainly developed for the recognition of handwritten numeric digits (Stylator, Bell Labs, late 1950s). Some proposals for an application in television fashion.
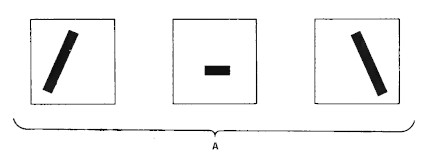
Feature analysis
Defining: What is the machine-idea of a certain letter or number? What are its features? One example is character stroke analysis: How many strokes, their positions, relations to other strokes. A plurality of mask arrays is necessary.
Links: Early Reading Machines
- [3] Alfred R. Sharples, Audible Reading Apparatus, U.S. Patent 2228782, 1941 – Patent document with illustrations and description ↩
- [4] Dietrich Walter (Standard Elektrik Lorenz), The Automatic Recognition of Typewritten Numbers, in: Proceedings of the IEE. Part B: Electronic and Communication Engineering, Vol. 106, No. 29, 1959, 446-447; Wilbur H. Highleyman (Bell Telephone Laboratories), Character Recognition System, U.S. Patent 2978675, 1961 – Patent document incl. illustration of probability matrices ↩
- [5] Mara Mills, Optophones and Musical Print, in: Sounding Out! The Sound Studies Blog, 05/01/2015; Tiffany Chan, Mara Mills and Jentery Sayers, Optophonic Reading, Prototyping Optophones, in: Amodern, No. 8, 01/2018 – Two articles/essays about the media history of the Optophone ↩
Common Confusion
Without given a context, by going through letter by letter, some characters are often mistaken. In particular when diacritical marks or ambiguous characters are present. Scripts with a lot of ligatures and overlaps like Arabic and Devanagari need an overall “segmentation-free” approach. [6]
- t l
- a ä å
- خ ج ح
A ‘Buch’ (English ‘book’) is commonly mistaken for a ‘Bucli’. Of course, you will find hundreds of Buclis in German books with a Google Books search. “Dafleihe Bucli kloss deutsch”, “dass das betreffende Bucli an sicli unsittliclie und unelirbare Dinge entlalte”.
Digital poetry is Nuttekaktersm, says German poet Dagmara Kraus. “Deutsche Classiker des Nuttekaktersm” became the title of a retro-digitized work by Franz Pfeiffer. It is a work about the literature classics of the middle-ages. ‘Mittelalters’ mistaken for ‘Nuttekaktersm’ is not a common confusion but so influential that physical reprints of the work now take a overridden title. [7]
- [6] Badr Al-Badr and Robert M. Haralick, Segmentation-free word recognition with application to Arabic, in: Proceedings of 3rd International Conference on Document Analysis and Recognition, Vol. 1, 1995, 355-359 ↩
- [7] Dagmara Kraus, Das googlitchige lórschapelekin. Deutsche Klassiker des Nuttekaktersm, in: perlentaucher.de, 08/2019 ↩
Machine-Usable Fonts

Humans are able to identify letters and numbers in a thousand of type styles. But machines need to be separately trained on certain sets of styles and their specific stroke width. Companies designed their own type styles for automatic recognition by a machine; with characters internally coded or bit-mapped. The most common way to achieve this encoding was to construct every character in a 5x7 (or 5x9) grid, with uniform width, minimum serifs and strong right edges. A single type font was standardized by the U.S. Bureau of Standards in 1968: OCR-A. Some years later in Europe, Adrian Frutiger designed OCR-B (applying a smaller grid) which became ISO standard in 1973.

- Zach Whalen, OCR and the Vestigial Aesthetics of Machine Vision, in: ZW. Blog, 03/01/2013
State-Of-The-Art 2020s
In the 2020s, Optical Character Recognition systems allow fewer ambiguities. They detect and classify noise and are able to normalize curved baselines. With the use of lexica the system will choose a common letter n-gram (‘ing’) over a unusual one (‘lng’). And so-called whitelists give the option to filter or recognize only a defined list of characters. An all-in solution: The ScanTent for scanning on the go with a smartphone.
Many engines use Neural Networks (DNN, CNN or LSTM) to apply OCR to material with specific characteristics; kraken for example is optimized for historical and non-Latin scripts. Calamari, which is based on kraken and OCRopy, takes line images instead of segmented individual characters and it preprocesses the images to a standardized height. Since version 4, Tesseract can go into Legacy (character patterns) or LSTM (line recognition) mode and with a JavaScript library it can run on a website.
Artworks with OCR
- Ranjit Bhatnagar, A Human Docum•nt, 2017 – Project for NaNoGenMo 2017. Used ABBYY’s online OCR to identify every ‘e’ in a book scan. A program then blots out all ‘e’.
- Liza Daly, A Letter Groove, GitHub, 2022 – Project for NaNoGenMo 2022. Uses hOCR data to cut out segments from scanned book pages. The cutouts reveal the pages beneath.
- Darius Kazemi, Reverse OCR – Bot that grabs a random word and draws semi-random lines until Ocrad recognizes it
- Jörg Piringer, datenpoesie, Klagenfurt; Graz: Ritter Verlag, 2018, 236–243 – A German text converted to image then converted back to text with OCR, 99 times. Based on mouse reeve’s Ozymandias.
- mouse reeve, Ozymandias, GitHub, 2017 – Program (Shell script) that converts a text file to an image and back using ImageMagick and Tesseract.